Physische Datenmodellierung
Was ist ein physisches Datenmodell?
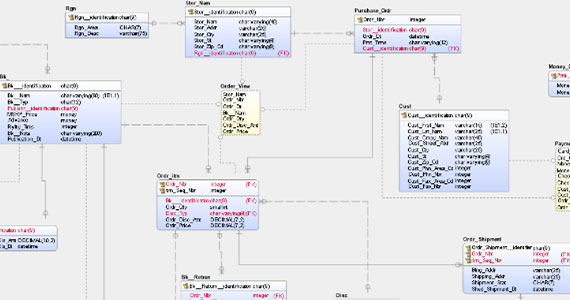
Ein physisches Datenmodell bringt datenbankspezifischen Kontext ein, der in konzeptionellen und logischen Datenmodellen fehlt. Es zeigt Tabellen, Spalten, Datentypen, Ansichten, Einschränkungen, Indizes und Verfahren innerhalb der Datenbank und/oder Informationen, die bei laufenden Rechenprozessen kommuniziert werden.
Physische Datenmodelle sollten entsprechend einem spezifischen Datenbankmanagemensystem (DBMS) und den besonderen Anforderungen von Prozessen erstellt werden, die basierend auf diesen Daten ablaufen. Hierzu ist häufig die Denormalisierung der logischen Designkonstrukte erforderlich, um die referenzielle Integrität zu bewahren. Kontextuelle Überlegungen auf der physischen Ebene der Datenmodellierung befassen sich beispielsweise mit der Art von Daten, die verarbeitet werden (können) und den Regeln, denen die Ausführung solcher Prozesse unterliegt.
Des Weiteren muss sichergestellt werden, dass die modellierten Spaltentypen im DBMS unterstützt werden und die Namenskonventionen für Entitäten und Spalten eingehalten werden, um problematische semantische Überlappungen zu vermeiden. Wenn der technologische Kontext berücksichtigt wird, spiegeln physische Datenmodelle die Anforderungen der technologischen Umgebung wider – und zwar so, wie sie tatsächlich vorliegt bzw. beabsichtigt ist.
Was ist das Ziel eines physischen Datenmodells?
Als datenbankspezifische Darstellung eine Datenmodellimplementierung helfen physische Datenmodelle dabei, die Struktur einer Datenbank zu visualisieren, bevor sie erstellt wird. Der Zweck und das letztendliche Ziel dieser Modelle ist die Implementierung einer Datenbank. Sie helfen Organisationen zudem dabei, indem sie beschreiben, wie die Datenbank im Rahmen der Einschränkungen eines bestimmten DBMS erstellt wird.
Datenbank-Designer können damit eine Abstraktion der Datenbank erstellen und Schemata generieren. Entitätstypen werden in Tabellen dargestellt und Beziehungslinien stehen für Fremdschlüssel zwischen Tabellen. Nur mit dieser Perspektive können Sie sicherstellen, dass Datenobjekte und Beziehungen in Organisationssystemen korrekt und kompatibel abgebildet werden.
Wann sollte ich physisches Datenmodell in Betracht ziehen?
Die drei Arten von Datenmodellen können und sollten als lineare Phasen betrachtet werden. Als dritte Phase der Datenmodellierung baut die physische Datenmodellierung auf den Modellen auf, die in den konzeptionellen und logischen Phasen entwickelt wurden.
Physische Modelle markieren einen Wendepunkt bei Modellen. Bisher wurden sie erstellt, um das „Was“ aufzuzeigen – also die Daten und Informationen, die modelliert werden. Jetzt dienen sie zur Darstellung der eigentlichen Implementierung. Natürlich werden bei diesem Implementierungsansatz die Besonderheiten des DBMS und der Technologie berücksichtigt, etwa die für das Projekt vorgeschlagenen Denormalisierungsanforderungen.
Das Modell beschreibt die Datenanforderungen eines einzelnen Projekts, es kann aber auch in physische Datenmodelle von anderen Projekten integriert sein, um die Beziehungen zwischen Projekten, Prozessen und Technologien zu berücksichtigen. Weil das physische Datenmodell spezifische Technologie berücksichtigt, ist es unflexibler und selbst geringfügige Änderungen können Modifikation an der gesamten Anwendung erforderlich machen. Es ist daher ratsam, erst dann mit der Erstellung eines physischen Datenmodells fortzufahren, wenn die konzeptionellen und logischen Datenmodelle erstellt wurden.
Warum sollte ich ein physisches Datenmodell nutzen?
Physische Datenmodelle sind ein wichtiges Mittel, um die Besonderheiten einer Implementierung nachvollziehen zu können. Je besser das Verständnis, desto wahrscheinlicher ist die erfolgreiche Implementierung einer Lösung, die den Anforderungen der Organisation entspricht.
Ein gut konzipiertes physisches Datenmodell verbessert die Datenqualität, vereinfacht die Implementierung und Wartung und erleichtert die Skalierung. Allerdings hängt ein wohl durchdachtes physisches Datenmodell auch davon ab, wie gut die vorhergehenden Modelle gelungen sind. Viele Organisationen sind sich tatsächlich bewusst, dass sie ein physisches Datenmodell erstellen sollten, beschönigen aber die konzeptionellen und logischen Modelle oder überspringen diese ganz. Dies führt unweigerlich zu Lücken bei Designüberlegungen und Problemen mit der Datenherkunft und der Nachverfolgbarkeit von Datenmodellen zu physischen Anwendungen.
Vorteile der physischen Datenmodellierung
Sie helfen dabei, die Datenbankstruktur visuell darzustellen.
Sie verringern das Risiko von misslungenen oder unvollständigen Implementierungen.
Das Datenmodell kann schnell in ein Datenbankschema umgewandelt werden.
Bessere Visualisierung Ihrer Daten mit erwin
Mit über 30 Jahren Erfahrung ist erwin ein zuverlässiger Anbieter von Tools für die Datenmodellierung und in diesem Bereich Branchenführer. Wir werden weiterhin Innovationen für jede Phase des Datenmodellierungsprozesses entwickeln und die Lücke zwischen der Datenmodellierung und den allgemeinen Bemühungen um die Daten-Governance schließen.
Benutzer des erwin Data Modeler von Quest profitieren von einer Plattform, welche die Zusammenarbeit fördert und gleichzeitig auf jede Phase des Datenlebenszyklus eingeht. Kunden mit dem erwin Data Modeler profitieren nicht nur von SQL- und NoSQL-Support bis hin zum automatisierten Harvesting von Metadaten, sondern auch von deutlich kürzeren Implementierungszeiten.