And my last use case is about AI models. So I will go again one more time to our entry screen, to our marketplace. And I will describe what we are doing around the AI models. So I have nine AI models described in my system.
So I'll pick a very obvious one. It's part of the risk domain. I have a fraud detection. I'll just quickly go there. First thing what we do is you have a nice description of what this AI model does. And a nice description, very transparent. Who owns this information? I mean, who owns this model? What is it intended to do?
And again, all the policies and the data sets I'll come back to it later. I can get some additional information about the model. I can even go to the AI model itself. I mean, if I want to just get my hands on the Jupyter notebooks and play with it and see what the model does, I can do that. I can see that it's in production. When was it last trained? If it's a relevant information, or what's the version number being deployed?
So in a nutshell, in this screen, what you are seeing is, what is this AI model? What it's supposed to do? Who owns it? And is it in production? Is it being used? Or is it still being developed?
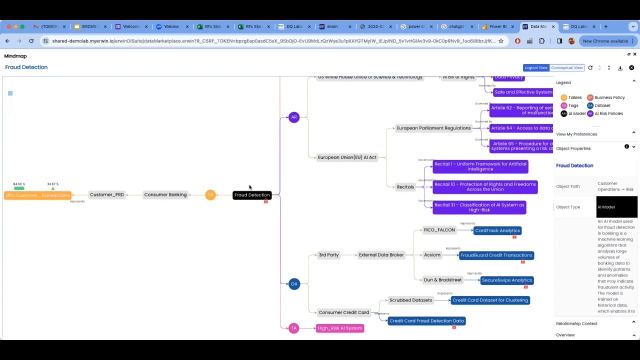
So let's go to the next page. Again, I'll go to our most popular, favorite view, which is the mind map. If I click on it-- and again, it gives me a 360 view of our AI model, in this case. And again, like I did in the previous screen, I'll just blow it up and bring all the information in.
And, oh, my god, what you see here is I have business policies because this model touches PII information. First of all, we are subject to CCPA. So it looks like it's somewhere in California.
And then I have all these regulations applying to that. And you have been seeing, as was mentioned, like, in European Union, in US, in China, in different areas of the world, there are all these AI regulations being published by the governments. So you have this information so you know what regulations apply to this particular AI model. So that's number two. So I know what I need to fulfill, what I need to comply with.
Number three, I'm looking at the data sets I used to train this model. And I realize some of them are third party. Some of them are actually synthetic data. I'm like, OK, that's interesting. So I'm using some synthetic-- not real-life but synthetically produced data to train this model, which is fine. I mean, it's a very common thing nowadays, using synthetic information to train models. But OK.
And then last but not least, I'm hearing-- I'm looking at a high risk. So if you look closer to the regulations, especially in the European Union regulations, the models are being classified by high risk, medium risk, and low risk. And most of the time, the classification-- I mean, you can, of course, read the definitions.
But in a nutshell, if your model is touching PII information, sensitive information, it's usually being categorized as a high-risk system. So you can see that it's being classified as high-risk system because it's touching PII. Then what rules apply, what kind of-- you need to watch out for the bias, things like that.
And this red icon, as I mentioned earlier, it tells you that this model is touching PII. It might be intentional. It might not be intentional. But by all means, you don't want bias, especially in a case like fraud detection, on personal information. So that's the third thing we do, is we look for all the regulations and especially the privacy regulations. And we make sure the models intentionally or unintentionally do not violate those codes.
So let's look at the data itself because we say the AI models are only as good as how the data is. And I can already see it's a green. It's 84% data quality. It's great. I'm using this table to feed this AI model. I have reasonable quality. But nevertheless, again, I'd like to drill down a little bit further to understand what's going on.
So again, once more time, we are drilling into some technical details. I can see that I'm looking at a table here, the credit card transactions table because it's doing the fraud analysis based on this table. And I can see the data quality.
But I'd like to see the quality at the column level. Now I can see at every column level. And some columns actually have lower quality than others. And I have drift alerts. So the fourth thing what I want to show you is the drift.
So if I click on this particular column, it takes me to an environment. It's our data quality, DQ lifespan environment, which I can drill into more details of the profiling and the quality. But what I want to focus is, today, drift because drift is so important for AI models. So you want to be able to catch drift as it happens, because if you don't catch and if you don't take measure, it might just hinder and impact the output of your model.
So I'm looking at the drift on the transaction category column for this table. And I can see I have defined several drift rules. And I can set some alerts. I said, OK, if the drift is higher than this threshold, just notify me. Let me know. And by clicking on it, I can see exactly what date the drift happened and how did it happen and how it is trending.
And it's live information. So this tool continuously, two, three times a day, looks for incremental changes in the data sets, look for changes, look
 07:52
07:52